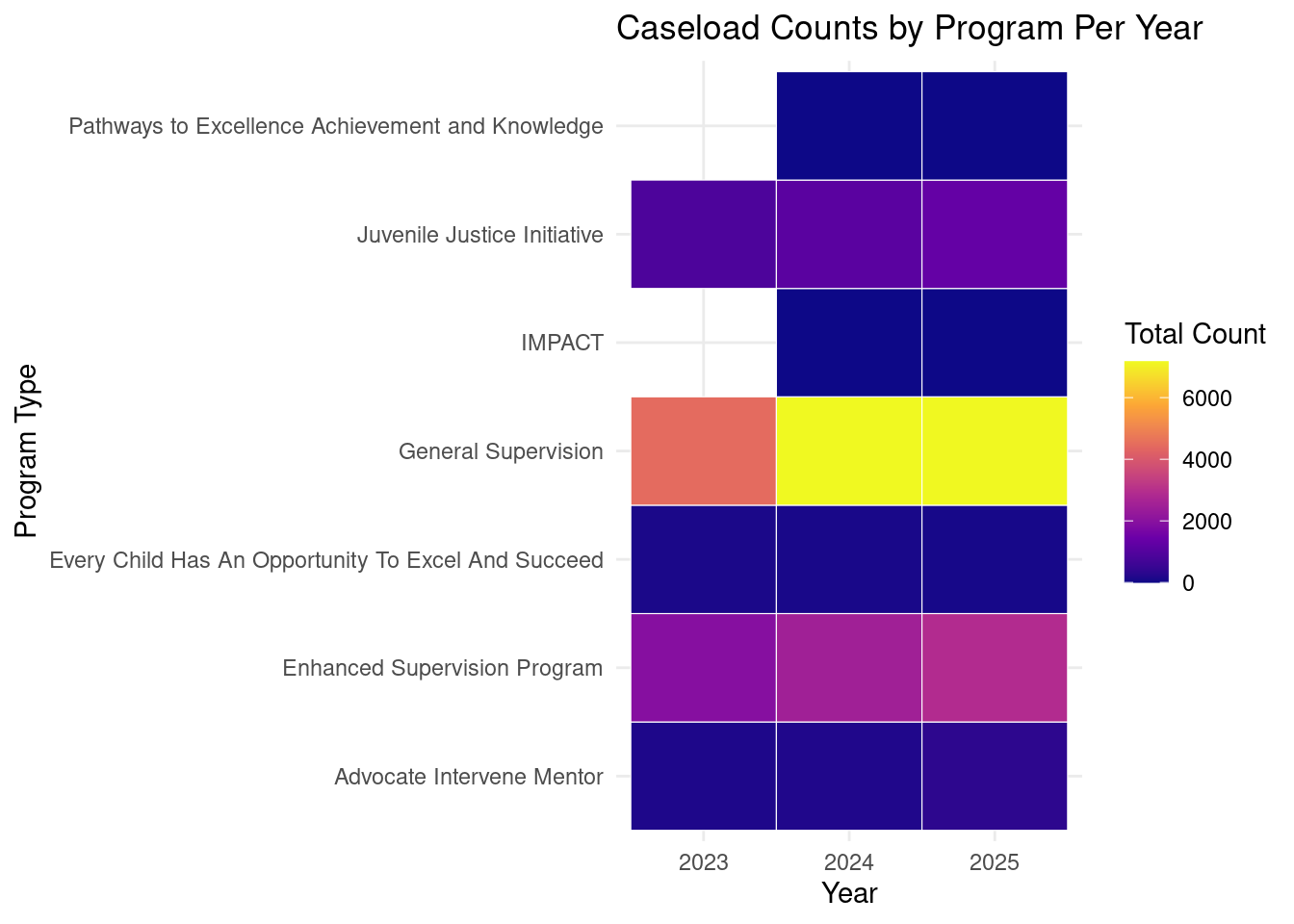
This is a project that I hope to present at the NYC OpenData conference next spring. I must admit that there are some datasets that I intended to use for this final assignment, but because of time and roadblocks, I will focus on the two keys datasets for now. My goal is to keep on this project by finding a meaningful way to include the other datasets. I believe that this project has the potential to become something special.
Show the code
library(tidyverse)
Warning: package 'tidyr' was built under R version 4.5.2
Warning: package 'readr' was built under R version 4.5.2
Warning: package 'purrr' was built under R version 4.5.2
── Attaching core tidyverse packages ──────────────────────── tidyverse 2.0.0 ──
✔ dplyr 1.1.4 ✔ readr 2.1.5
✔ forcats 1.0.1 ✔ stringr 1.6.0
✔ ggplot2 4.0.0 ✔ tibble 3.3.0
✔ lubridate 1.9.4 ✔ tidyr 1.3.1
✔ purrr 1.2.0
── Conflicts ────────────────────────────────────────── tidyverse_conflicts() ──
✖ dplyr::filter() masks stats::filter()
✖ dplyr::lag() masks stats::lag()
ℹ Use the conflicted package (<http://conflicted.r-lib.org/>) to force all conflicts to become errors
Show the code
library(dplyr)library(Hmisc)
Warning: package 'Hmisc' was built under R version 4.5.2
Attaching package: 'Hmisc'
The following objects are masked from 'package:dplyr':
src, summarize
The following objects are masked from 'package:base':
format.pval, units
Show the code
library(ggplot2)library(corrplot)
corrplot 0.95 loaded
Show the code
library(lubridate)library(nycOpenData)
6.1 Let’s load the dataset
Show the code
rea <- nycOpenData::nyc_dop_juvenile_rearrest_rate(limit=10000)head(rea)
# A tibble: 6 × 4
borough month year rate
<chr> <chr> <chr> <chr>
1 Citywide September 2025 4.5
2 Citywide December 2025 4.4
3 Citywide July 2025 5.3
4 Citywide October 2025 4.4
5 Citywide August 2025 4.6
6 Citywide November 2025 4.5
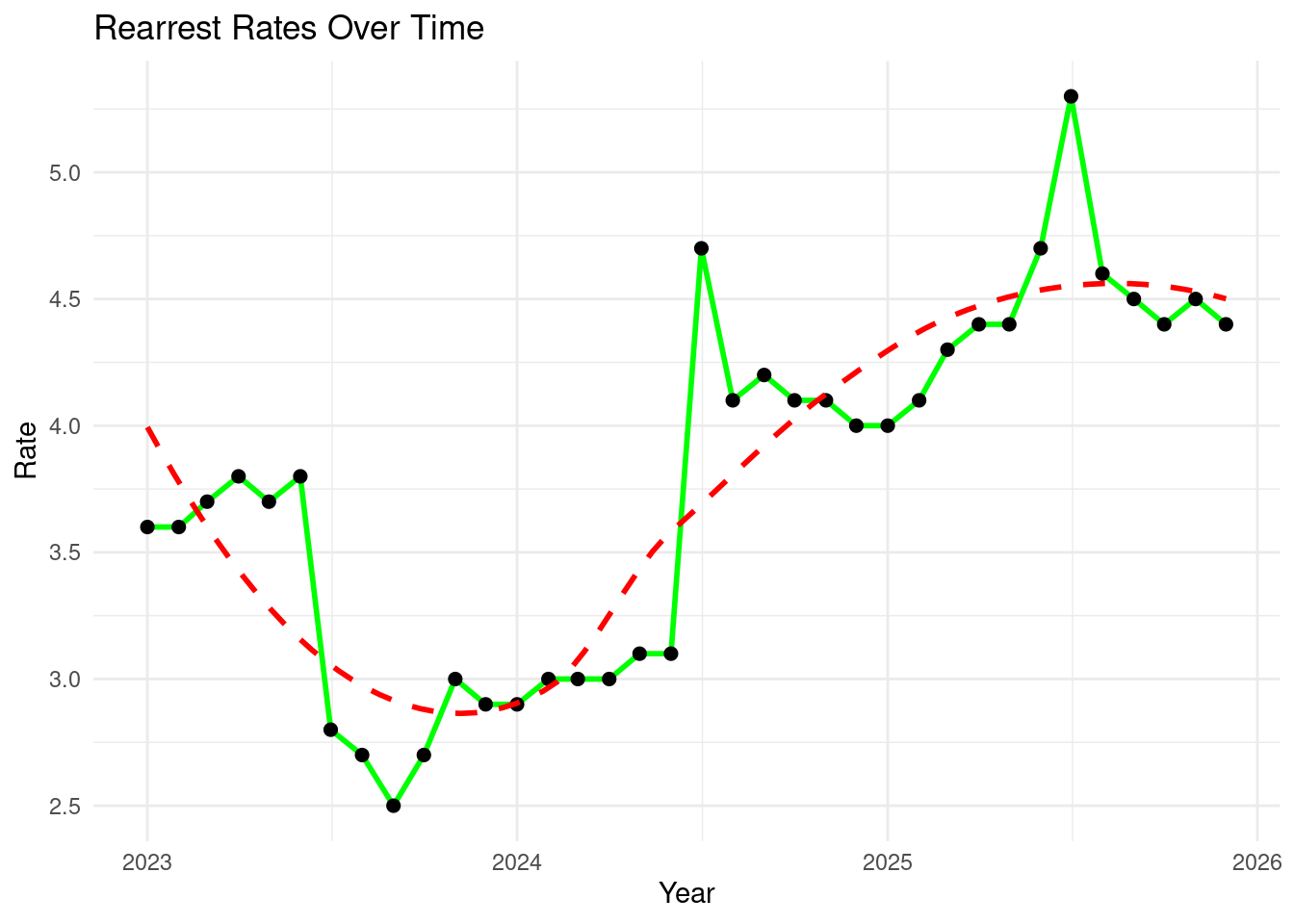
6.2 Let’s focus on the years between 2023 and 2025
Show the code
rea_clean <- rea %>%filter(year >=2023& year <=2025)head(rea_clean)
# A tibble: 6 × 4
borough month year rate
<chr> <chr> <chr> <chr>
1 Citywide September 2025 4.5
2 Citywide December 2025 4.4
3 Citywide July 2025 5.3
4 Citywide October 2025 4.4
5 Citywide August 2025 4.6
6 Citywide November 2025 4.5
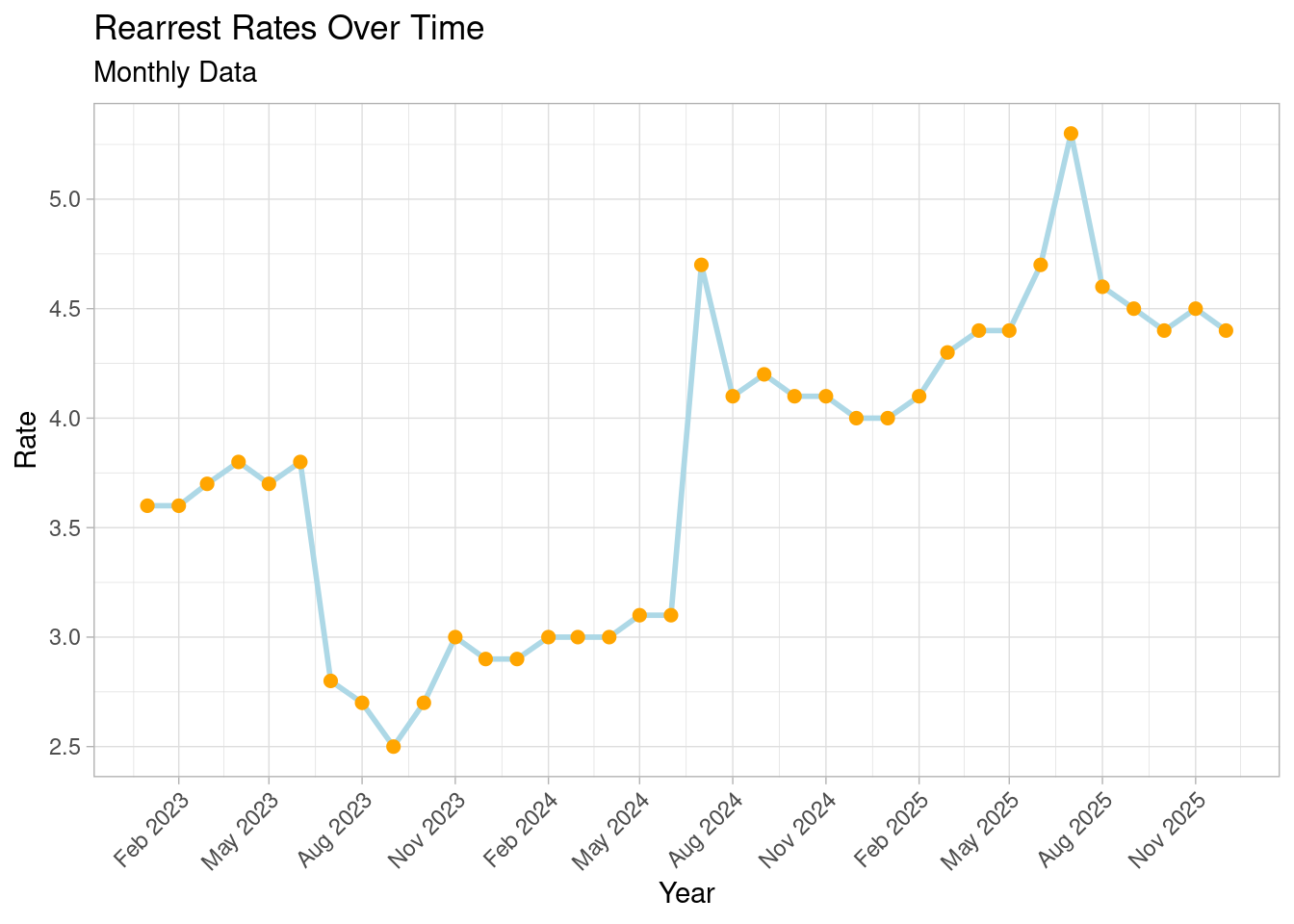
6.3 Let’s create a new column that contains month and year
# A tibble: 12 × 2
month mean_rate
<ord> <dbl>
1 Jan 3.5
2 Feb 3.57
3 Mar 3.67
4 Apr 3.73
5 May 3.73
6 Jun 3.87
7 Jul 4.27
8 Aug 3.8
9 Sep 3.73
10 Oct 3.73
11 Nov 3.87
12 Dec 3.77
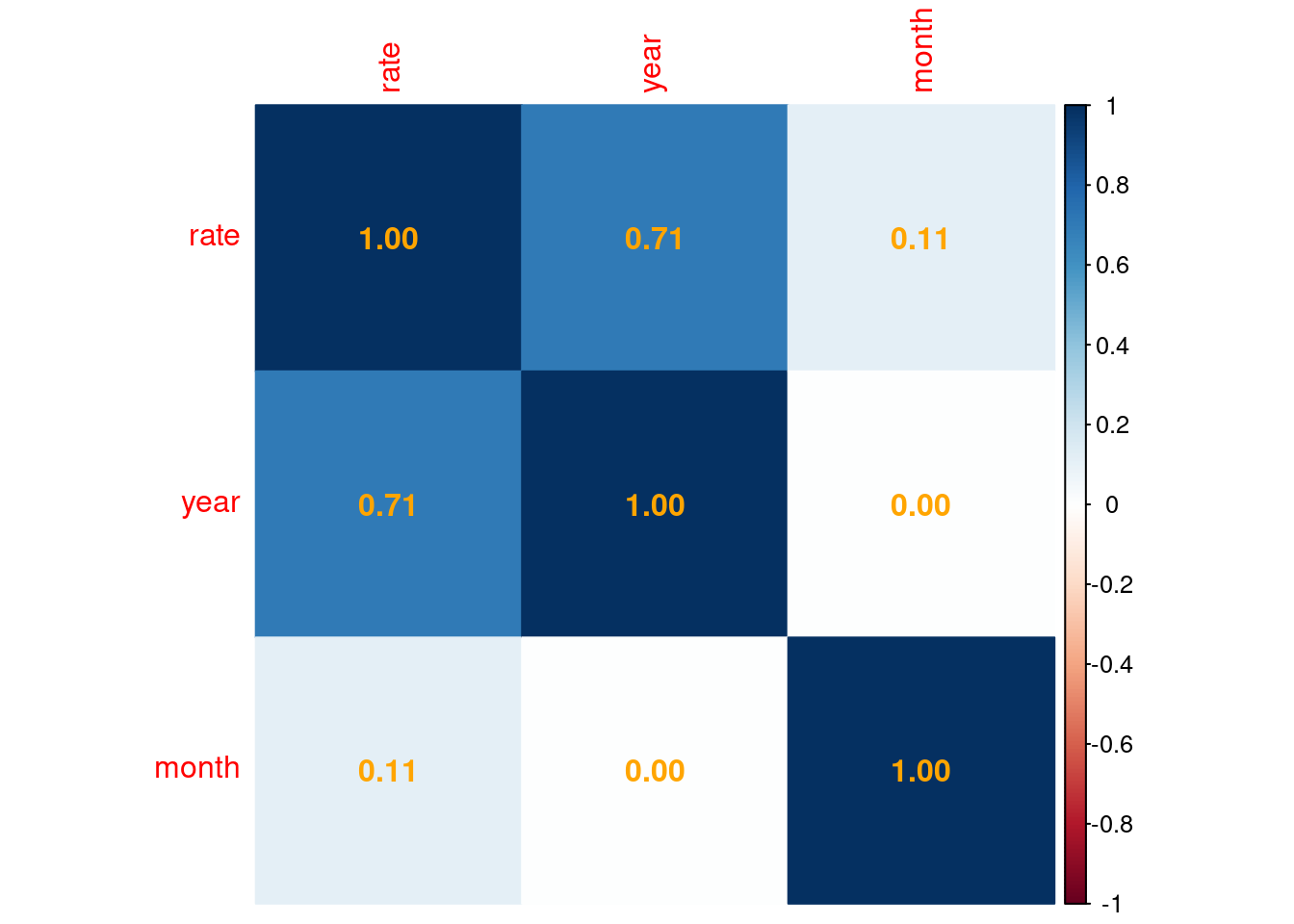
6.9 Let’s finally see if we can find a correlation between rearrest rates and year